
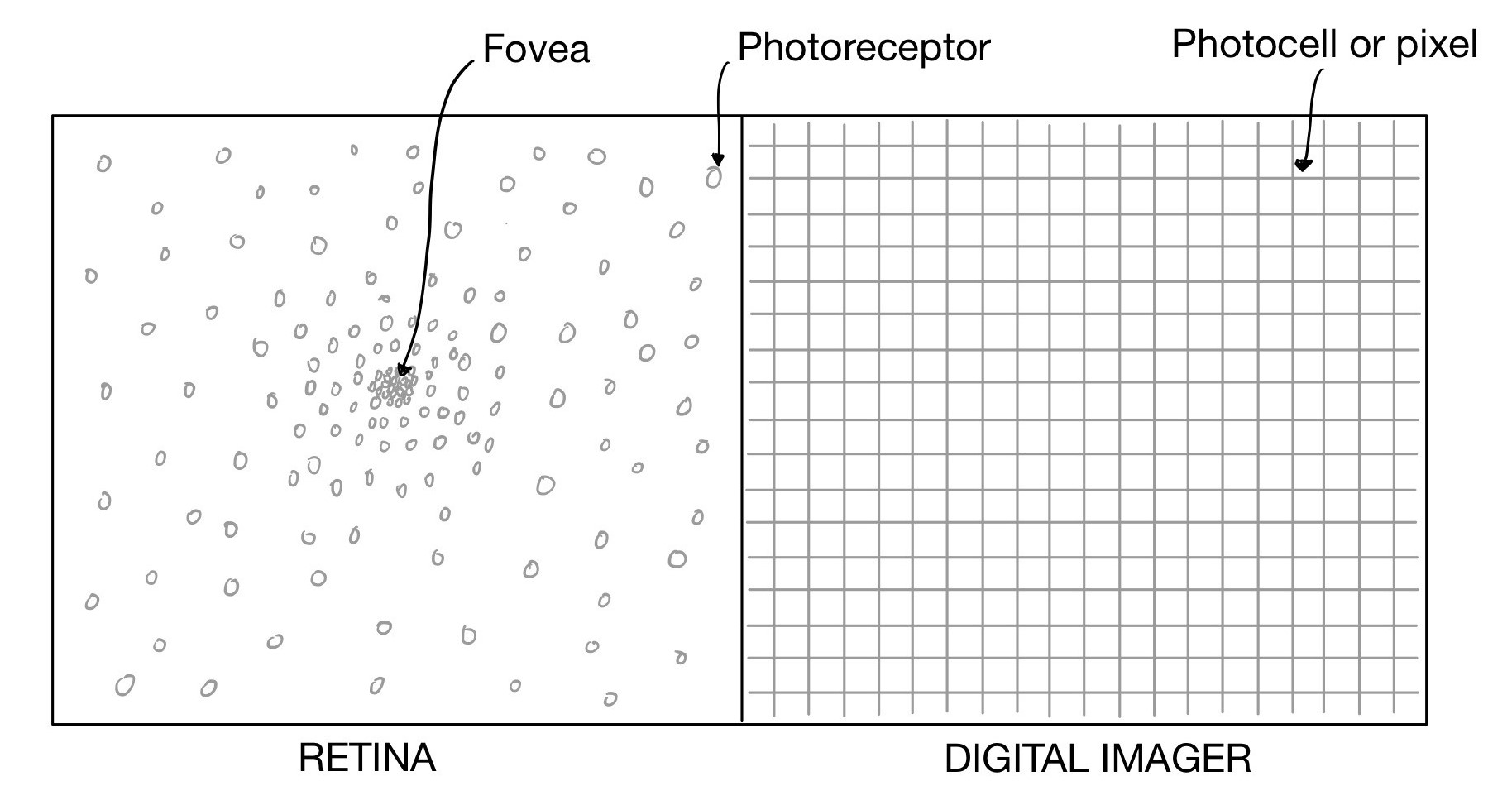
We move our eyeballs constantly whereas most robots have fixed cameras. Common knowledge is that humans move their eyes so much because of the quirks in the sensory apparatus. That is, the retina doesn’t have an even distribution of photoreceptors–basically different regions of the retina have different “megapixels”. So it makes sense to expose the area of the retina with maximum resolution to things that are of interest. But most modern cameras don’t have this problem—they have sensors evenly distributed on a rectangular grid. So should robots bother moving their cameras like us? In this article you’ll find out that it indeed is very useful for 3D perception!
1 Gaze and Eye Movements
I should be more precise when I say “move their eyes like us”. Largely, human eye movements can be categorized into two kinds: saccadic and fixational movements, that correspond to changing and maintaining gaze respectively. Eye saccades are rapid jumps of your eyes, e.g., when you are reading this and your gaze is rapidly shifting focus from one word (group) to the next in the sentence. You do it at least a 100,000 times a day (Irwin, Carlson-Radvansky, and Andrews 1995). The other is fixation (or smooth pursuit) where you “track” objects as they move with respect to you, either because of your own movement or objects’. The scope of eye movements in this article is limited to fixational movements.
2 Structure from Motion
It is possible to recover 3D structure of a scene from a moving 2D sensor. When you move, you experience this as objects moving at different speeds depending on their distance. As an example, consider the moon that seems to follow you wherever you go, as opposed to buildings and trees. Since the moon is very far from you, its apparent shift in your visual field is miniscule. So small that it seems to follow you everywhere. But a tree in front of you sweeps past you as you move past it. This is called motion parallax (strictly with translations, as in Figure 3 (a)), and you can in principle work out relative depth order of objects you’re interested in by measuring how much they moved with respect to you.


All this is common knowledge, but what is not understood well is the role of fixation. How does locking your gaze at an object while you move help in structure from motion, if at all? It turns out, when you fixate, you can determine depth order in a simpler way: measuring the direction of motion instead of how much objects moved. The specific compensatory eye/camera rotations also intimately relates to the distance to the object being fixated.
The important thing to take away is that fixation is nothing new, but forces motion parallax to be represented a new way. Instead of “pure” structure from motion where effects of rotations are ignored, fixation craftily injects rotations to make 3D perception relative to specific objects. It is an alternate, but a very useful representation.
2.1 Ok, So What?
I am suggesting that moving the robot camera to look at one object at once gives 3D information in a different way. The 3D information is not represented in the way traditionally understood using motion parallax (in computer vision). So what? Why even bother getting a different representation? And at what cost? Introducing new mechanical parts to move the camera? Isn’t it generally a bad idea to introduce moving components?

Yes and no. It of course depends on the robotic task. If your robot is a manipulator (e.g., Franka Emika Robot) with a camera attached to it, this actually adds little cost. If your robot has its camera on a gimbal (e.g., a drone), it adds no cost to do this. But if your robot is an autonomous vehicle, the benefit of adding additional components to actively move the camera is not clear. Nevertheless, there are potentially many robotic applications that can take advantage of fixation and you will see how if you read on.
3 Taking Advantage of Fixation
3.1 Relative Depth
In Section 2, we briefly saw how direction of movement is indicative of depth order. To understand this in a deeper manner, try this interactive app. Dragging your mouse in different directions is equivalent to moving laterally while fixating on the purple diamond object. You can observe how the other objects move in different directions depending on their relative location to the diamond–objects behind always move in the opposite direction of objects in front1. Turn on the arrows (bottom-left button) for clarity.
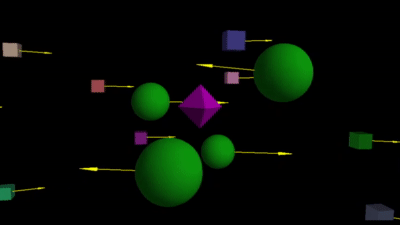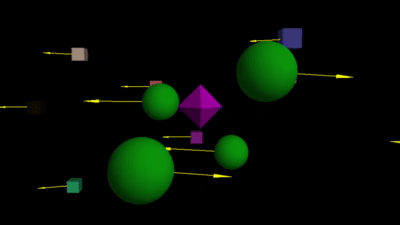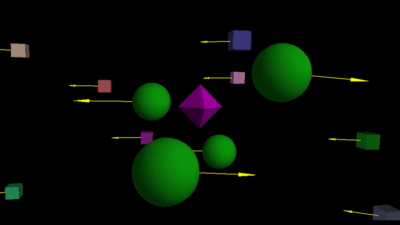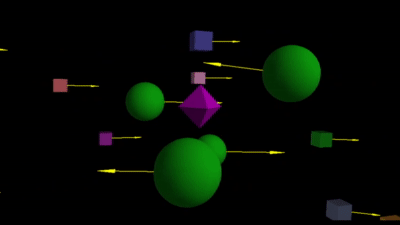
The relative movement straight-forwardly filters out objects of interest. For a robot, objects closer to an object-of-interest is possibly an obstacle. So it can be aware of such objects, whereas all the objects behind the object-of-interest maybe ignored!
3.2 Absolute Depth (Distance)
Fixation gives access to another less obvious but immensely helpful 3D cue: absolute distance to the fixated object. If you take a look at the interactive app again, notice that as the camera is fixating, any lateral movement (translation) is accompanied by compensatory rotation to maintain the diamond in the same position in visual field. This basically constrains the trajectory of the camera in a very specific way—no matter the distance or (lateral) velocity, it will ensure the camera revolves around the diamond!
Some drones revolve around a “hotpoint”, specified by some radius, resembling the motion a camera would take when fixating. The crucial difference is that you don’t need to specify a distance for the camera to revolve around, but the camera ends up following this motion if it simply keeps the object-of-interest in its center of view!

Better still, you can turn around the rate of rotation to measure distances! Intuitively, farther objects require lesser compensatory rotations of the camera. So, if a robot is able to measure the instantaneous rotation rate, it can immediately work out the distance to the fixated object.
3.3 Why Fixation?
Let me come back to the why question again. Why perform fixation on robot? If you are interested to do almost any real-world task with a robot, it would involve actually moving some part(s) of the robot. If you simply modify the behavior of the robot such that under movement it only looks at one object at a time, then you get relevant information with respect to interacting with those objects for free! That is, you get robust information about other objects in the way (and background), and distance to fixated object at no extra cost! No need for a fancy 3D sensor!
A subtler other advantage is the object-centric frame of reference. When fixated, “forward” direction always coincides with moving toward the object, and “up/down” and “left/right” are always with respect to the object. This liberates the robot from keeping track of some arbitrary world origin to reference every object with, and hence it is easy to change reference points without adverse effects.
4 How Good Is This Stuff?
On robotic experiments with a manipulator, it turns out to be pretty good! A robot can be tasked to pick up objects of unknown size even when there are unmodeled obstacles. The robot receives all visual inputs from an RGB camera that is no better in quality than an off-the-shelf webcam. And all compute/control is performed on a desktop PC without a dedicated GPU.
You can find more details about the robotic application in the paper here.
5 Connections to Other Things
Stereo. When using two cameras on a robot, instead of finding epipolar constraints, the problem of 3D perception can be simplified by rotating both cameras to fixate on an object. Humans unsurprisingly do this too by “verging their eyes”. Again, just like structure from motion Section 2, actively rotating both eyes/cameras produces an easy and robust representation for a robot.
Event camera. These neuromorphic cameras measure visual movement efficiently and with greater fidelity. As signals pertaining to Section 3.1 and Section 3.2 effectively measure visual movement, event cameras find a natural use here. Note, normal (frame-based) cameras cannot be dispensed as they are required to sense objects-of-interest in the first place. Event cameras can only help in efficiently measuring visual movement.
6 Important links
- Interactive app to visualize fixation: link
- Advanced version of interactive app: link
- Paper page: link
Update: June 30, 2024; fix typo; change video mkv to mp4 for wider compatibility; add Important links section.
References
Footnotes
Reuse
Citation
@online{battaje2022,
author = {Battaje, Aravind},
title = {Why {Should} {Robots} {Move} {Their} {Eyes} {Like} {Us?}},
date = {2022-07-08},
url = {https://oxidification.com/posts/2022-07-08_why_should_robots_move_their_eyes_like_us/},
langid = {en}
}